Back to Blog
The Context Window Expansion and What It Means for Your Business
StableWorks
Context windows expanded 1,000x in five years, enabling AI to process entire contracts, codebases, and document libraries in one pass. Practical guide to capabilities, limitations, costs, and when to use long context versus RAG.
Nov 24, 2025
Back to Blog
The Context Window Expansion and What It Means for Your Business
StableWorks
Context windows expanded 1,000x in five years, enabling AI to process entire contracts, codebases, and document libraries in one pass. Practical guide to capabilities, limitations, costs, and when to use long context versus RAG.
Nov 24, 2025
Back to Blog
The Context Window Expansion and What It Means for Your Business
StableWorks
Context windows expanded 1,000x in five years, enabling AI to process entire contracts, codebases, and document libraries in one pass. Practical guide to capabilities, limitations, costs, and when to use long context versus RAG.
Nov 24, 2025

Five years ago, AI models could process about 2,000 tokens at once. That's roughly five pages of text. Today, leading models handle over 2 million tokens in a single request. That's the equivalent of processing 15 full-length novels simultaneously.
This represents a genuine shift in what AI can do for businesses. Tasks that once required complex workarounds, document chunking, or simply weren't possible are now straightforward. For traditional organisations exploring AI, understanding this shift matters more than memorising model specifications.
From Pages to Libraries: How We Got Here
The trajectory of context window growth tells an interesting story. GPT-3 launched in 2020 with a 2,048 token limit. By 2023, models like GPT-4 and Claude 2 reached 32,000 tokens. Then came 2024's breakthroughs: GPT-4 Turbo hit 128,000 tokens, and Google's Gemini demonstrated 10 million tokens in research settings.
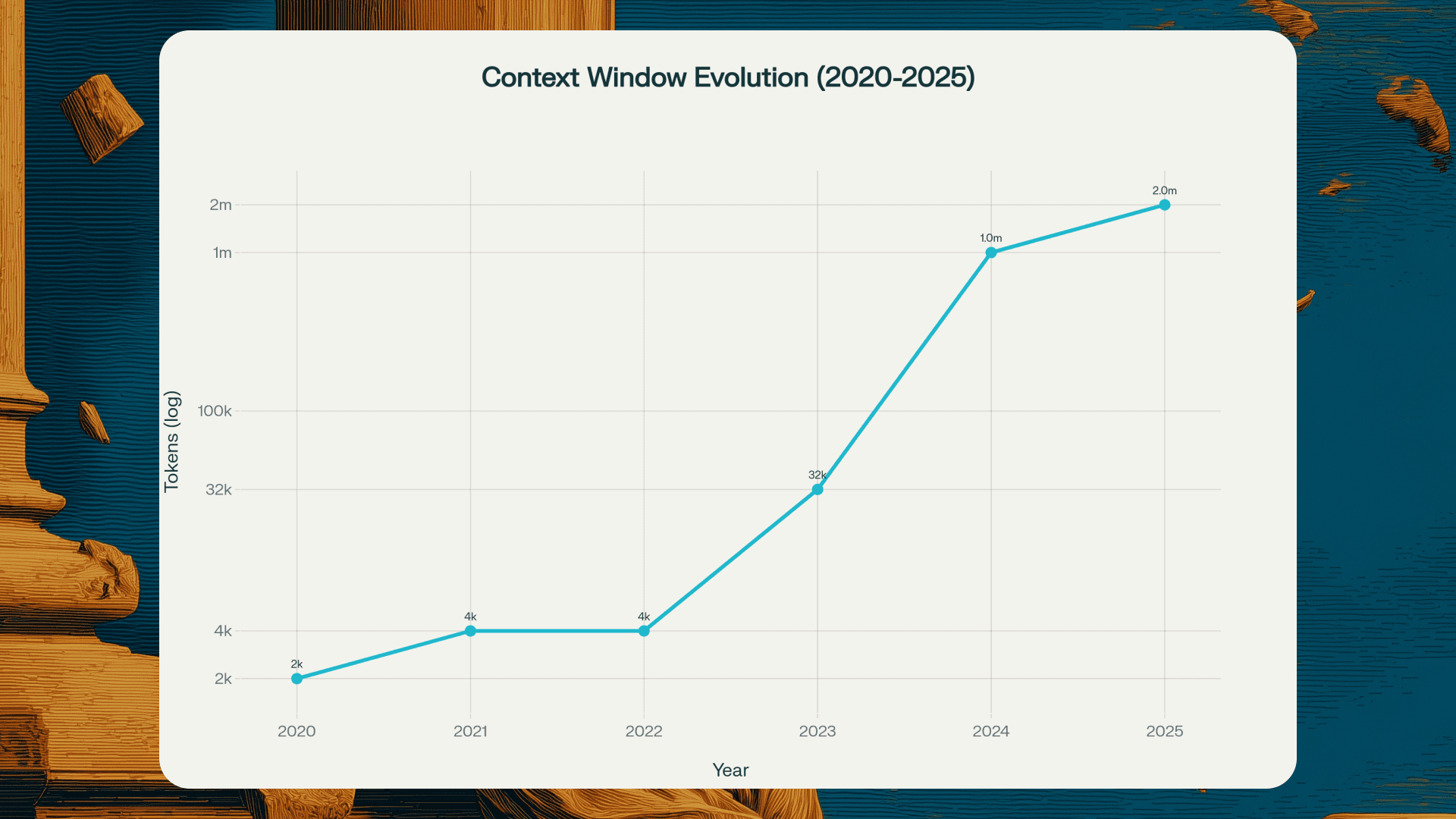
As of November 2025, the landscape looks remarkably different. Google's Gemini 3 Pro, released just last week, supports 1 million tokens with enhanced reasoning capabilities. OpenAI's GPT-4.1 family offers 1 million tokens across its variants. Claude Sonnet 4 recently expanded from 200,000 to 1 million tokens. GPT-5 provides 400,000 tokens with a focus on reliability and reduced hallucinations.
Perhaps most notably, OpenAI's GPT-5.1-Codex-Max, released on November 19, 2025, introduces a "compaction" technique that effectively eliminates context window limits altogether. It can manage entire software projects over millions of tokens by intelligently pruning its history while preserving critical context.
To put this in practical terms: a million tokens translates to roughly 750,000 words, or about 1,500 pages of text. You can now feed an AI system an entire regulatory framework, a complete codebase with documentation, or years of customer correspondence in a single request.
What This Actually Enables
Legal and Compliance Work
Law firms and compliance teams can now analyse entire contracts without breaking them into fragments. A 500-page merger agreement, roughly 375,000 tokens, can be processed in a single pass. The model identifies key clauses, flags potential conflicts, and maintains awareness of how provisions in section 3 relate to definitions in section 47. This wasn't reliably possible when documents had to be chunked into smaller pieces.
Research on automated building code interpretation shows that long context models can handle entire legal document corpora without requiring retrieval systems or fine-tuning. Domain-specific models processing regulatory and financial texts achieve over 81% accuracy on complex question-answering tasks when given full document context.
Financial Analysis
Financial analysts no longer need to extract isolated metrics from annual reports. They can process entire filings, earnings transcripts, and regulatory submissions together, understanding nuanced relationships between operational metrics and strategic initiatives. Studies using extended financial datasets demonstrate that long context processing enables more sophisticated reasoning than extraction-based approaches.
Market research firms can analyse thousands of customer feedback entries simultaneously, identifying patterns that would be invisible when reviewing individual comments in isolation.
Software Development
This is where the transformation has been most dramatic. Developers can now load entire codebases, including source files, tests, and documentation, into context. The model understands project architecture, identifies cross-file dependencies, and suggests improvements that account for the complete system design.
Multi-agent systems using long context for fault localisation have successfully identified 157 out of 395 bugs with top-1 accuracy on standard benchmarks, outperforming approaches that only see isolated code fragments. The shift from file-level to project-level understanding changes what's possible in automated code review and refactoring.
Enterprise Knowledge Management
Organisations can create knowledge assistants that genuinely understand relationships across their document collections. Rather than returning keyword-matched excerpts, these systems provide coherent answers that synthesise information from technical manuals, compliance documents, and operational guides. A manufacturing company can build a support system that references multiple sources while maintaining awareness of product-specific constraints.
The Limitations You Need to Know
Before restructuring your entire AI strategy around long context, it's worth understanding the current limitations. The technology is powerful, but comes with constraints.
The "Lost in the Middle" Problem
Research consistently shows that models perform best when critical information appears at the beginning or end of the context window. Information buried in the middle often gets overlooked, even in models specifically designed for long contexts. This creates a characteristic U-shaped accuracy curve across positions.
The mechanism behind this is architectural: attention layers in transformer models cause earlier parts of input sequences to be used more frequently during reasoning. As models add more layers, this positional bias amplifies. While newer models have improved, the effect persists. Gemini 3 Pro's benchmark results on 1 million token retrieval tasks show meaningful improvement over previous generations, but performance still varies significantly based on where relevant information appears.
For practical applications, this means you shouldn't simply feed a large document into a model and expect consistent accuracy across all sections. Strategic prompt construction, placing critical information at the beginning when possible, improves results.
Context Length Itself Hurts Performance
Research from 2025 reveals something more troubling: longer contexts degrade performance even when retrieval isn't an issue. Systematic experiments across major models on maths, question answering, and coding tasks showed that even with all relevant information placed at the optimal beginning position, performance still dropped 14% to 85% as input length increased.
This suggests limitations in how transformers process extensive context during reasoning, beyond simple attention mechanism issues. The practical implication: more context isn't always better. Sometimes a well-curated subset of information produces superior results to dumping everything into the prompt.
Reliability Variations
Stress testing reveals significant reliability differences between models. Some achieve over 96% accuracy with graceful degradation across 100,000+ tokens. Others, despite strong standard benchmark scores, collapse to near-zero accuracy under context stress, exhibiting confident hallucination from early checkpoints.
Model size alone doesn't predict reliability. Testing and evaluation matter enormously when selecting models for production applications that depend on long context accuracy.
Long Context vs RAG: A Practical Framework
One of the most common questions we encounter at StableWorks is whether organisations should use long context models directly or implement Retrieval-Augmented Generation (RAG) architectures. The answer depends on your specific situation.
When Long Context Works Best
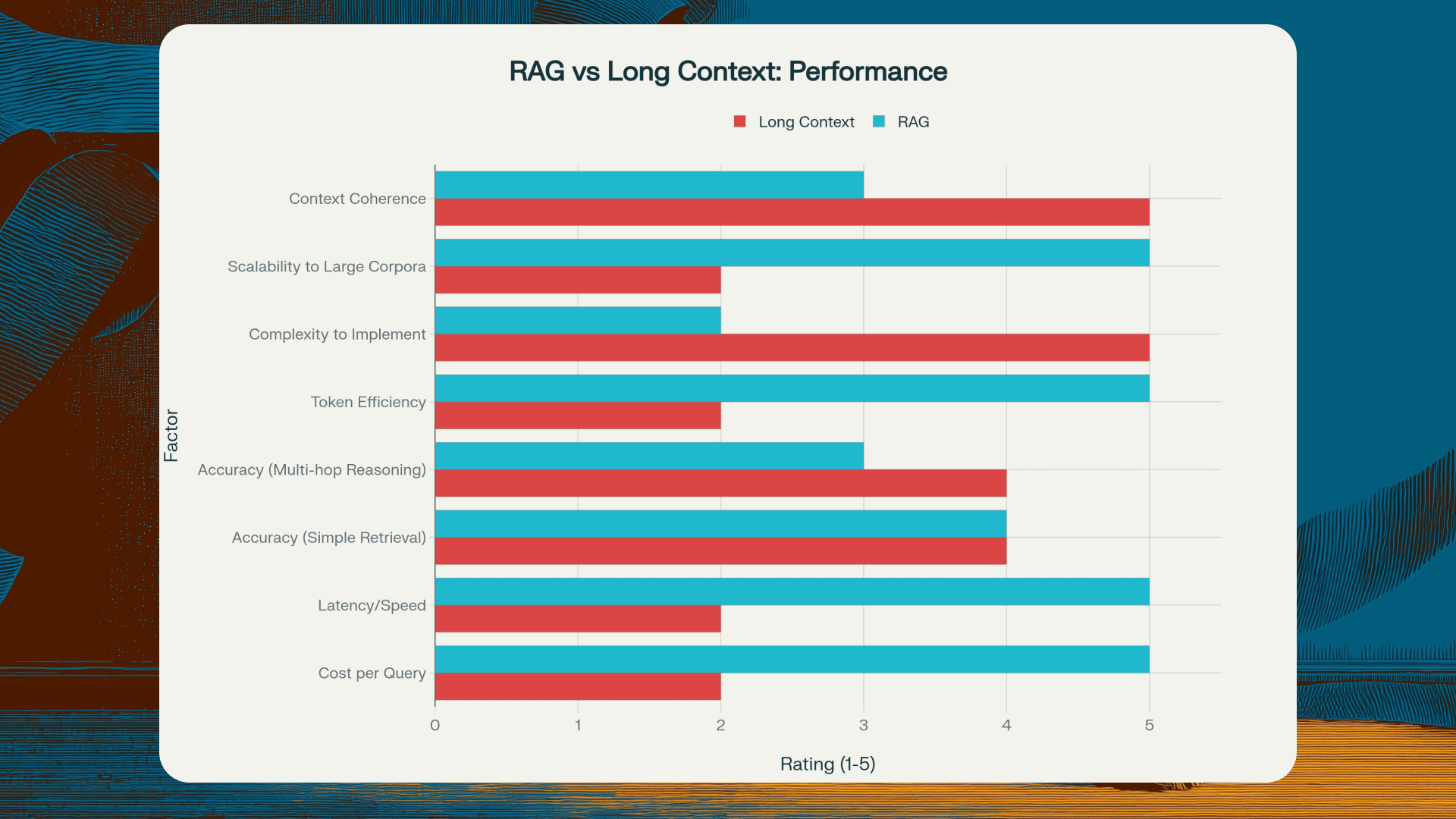
Long context approaches excel when your data is relatively self-contained and under 1 million tokens. If you're analysing a single book, a complete codebase, or a lengthy contract, direct processing often produces better results. Tasks requiring understanding of relationships between widely separated sections benefit from having everything in context. Literary analysis, architectural design review, and legal document interpretation often fall into this category.
Long context also makes sense when query volume is low enough that higher per-query costs are acceptable, when documents have complex internal cross-references that chunking would break, or when privacy regulations mandate keeping everything on-premise without external vector databases.
When RAG Makes More Sense
RAG architectures shine when your knowledge base exceeds available context windows, which remains common despite expanded limits. If you're searching across terabytes of documents, RAG's pre-filtering becomes essential. Cost and latency constraints also favour RAG: real-world testing shows RAG queries can cost 1,250 times less than full long context processing, with response times of 1 second versus 45 seconds for million-token contexts.
RAG also provides better explainability and citation capabilities. When you need to trace exactly which source documents informed an answer, retrieval systems make this straightforward. For customer support applications requiring real-time response, RAG's speed advantage is often decisive.
The Hybrid Approach
Increasingly, sophisticated deployments combine both approaches. Use RAG to identify relevant documents from a massive corpus, then apply long context processing for deep analysis of the filtered set. This achieves 3-5x cost reductions versus pure long context while maintaining 95%+ accuracy.
Emerging architectures like "Order-Preserving RAG" find optimal chunk counts, typically 20-30% of full context, achieving higher quality with fewer tokens than either pure approach. These hybrid systems represent where enterprise AI is heading: intelligent routing that selects the right approach for each query automatically.
Cost Realities
Understanding pricing is essential for budgeting and architecture decisions. Current rates vary significantly across providers.
Gemini 3 Pro costs $2 per million input tokens and $12 per million output tokens for prompts under 200,000 tokens, doubling beyond that threshold. Claude Sonnet 4 charges $3/$15 per million tokens for standard contexts, increasing to $6/$22.50 for contexts exceeding 200,000 tokens. GPT-5 prices at $1.25/$10 per million tokens for the standard model, with nano variants available at $0.05/$0.40.
Context caching transforms economics for applications with repeated queries against similar documents. Cached tokens typically cost 90% less than fresh tokens. For a document Q&A system processing 1,000 queries against the same 100,000 token knowledge base, caching reduces costs from roughly $100-125 to $10-15 after initial cache population.
Model cascading offers another optimisation path: route simple queries to inexpensive models while reserving premium models for complex reasoning. Well-implemented cascading systems achieve 87% cost reduction by ensuring expensive models handle only the 10% of queries requiring their capabilities.
Security and Privacy Considerations
Long context processing introduces distinct data privacy challenges. When you upload entire document repositories to cloud-based APIs, you're potentially exposing sensitive business information, customer data, and intellectual property. While enterprise providers offer privacy assurances, including commitments not to train on customer data, regulatory frameworks like GDPR and HIPAA often mandate stricter controls.
The unintentional exposure risk increases with context window size. Employees may inadvertently include confidential information when uploading large documents. Robust data protection requires employee training, automated scanning for sensitive content, and strict access controls.
For highly regulated industries, on-premise deployment of open-source long context models often becomes necessary despite their operational costs and typically shorter context windows. This allows organisations to maintain complete data control while meeting compliance requirements.
What's Coming Next
The trajectory suggests continued expansion, with 5-10 million token windows expected to become standard in flagship models by 2026. However, the emphasis is shifting from raw capacity to effective utilisation. Advertising a 10 million token window means little if models can't reliably use information throughout that range.
Infinite context approaches, like Google's Infini-attention, maintain compressed memory of previously processed content while handling new information. These systems could theoretically process unlimited context with bounded computational resources. Early demonstrations show 114x memory compression while maintaining over 99% retrieval accuracy.
The emergence of "compaction" techniques in models like GPT-5.1-Codex-Max hints at a future where context window limits become less relevant. Instead of hard capacity constraints, models will intelligently manage what they remember based on relevance and task requirements.
Multimodal integration will mature substantially. Current models handle text, images, and code, but future systems will seamlessly process video, audio, and interactive elements within unified long context frameworks. This enables applications like analysing hours of video meetings alongside associated documents and communications in a single context.
Practical Recommendations for Traditional Businesses
For organisations beginning to explore these capabilities, a few principles apply.
Start with constrained pilots. Choose a specific use case, perhaps contract analysis for your legal team or codebase documentation, and test thoroughly before expanding. Long context processing isn't uniformly superior; discover where it genuinely outperforms alternatives in your context.
Test positioning sensitivity. Before deploying, experiment with placing critical information at different positions within your prompts. If results vary dramatically based on where key details appear, your use case may require additional engineering to work reliably.
Consider hybrid architectures from the start. Pure long context approaches rarely offer optimal cost-performance trade-offs. Design systems that can intelligently route between RAG and long context processing based on query characteristics.
Budget for caching infrastructure. If you're processing repeated queries against similar documents, context caching transforms economics. Build this into your architecture rather than treating it as an optimisation for later.
Evaluate models under stress. Standard benchmarks don't reveal how models behave at the edge of their capabilities. Test with your actual document sizes and complexity levels before committing to a specific provider.
The Bottom Line
The expansion of context windows from thousands to millions of tokens represents a genuine capability shift. Tasks that were previously impossible, impractical, or required significant engineering workarounds are now accessible through straightforward API calls.
That said, long context isn't a universal solution. Understanding where it excels, where it struggles, and how to optimise costs matters as much as understanding that the capability exists. The organisations that benefit most will be those that approach these tools thoughtfully: identifying specific use cases where extended context genuinely helps, testing rigorously before deployment, and building hybrid systems that use the right approach for each task.
The context window revolution is real. Making it work for your business requires treating it as a powerful tool with specific strengths and limitations, rather than a magic solution to all document processing challenges.
Five years ago, AI models could process about 2,000 tokens at once. That's roughly five pages of text. Today, leading models handle over 2 million tokens in a single request. That's the equivalent of processing 15 full-length novels simultaneously.
This represents a genuine shift in what AI can do for businesses. Tasks that once required complex workarounds, document chunking, or simply weren't possible are now straightforward. For traditional organisations exploring AI, understanding this shift matters more than memorising model specifications.
From Pages to Libraries: How We Got Here
The trajectory of context window growth tells an interesting story. GPT-3 launched in 2020 with a 2,048 token limit. By 2023, models like GPT-4 and Claude 2 reached 32,000 tokens. Then came 2024's breakthroughs: GPT-4 Turbo hit 128,000 tokens, and Google's Gemini demonstrated 10 million tokens in research settings.
As of November 2025, the landscape looks remarkably different. Google's Gemini 3 Pro, released just last week, supports 1 million tokens with enhanced reasoning capabilities. OpenAI's GPT-4.1 family offers 1 million tokens across its variants. Claude Sonnet 4 recently expanded from 200,000 to 1 million tokens. GPT-5 provides 400,000 tokens with a focus on reliability and reduced hallucinations.
Perhaps most notably, OpenAI's GPT-5.1-Codex-Max, released on November 19, 2025, introduces a "compaction" technique that effectively eliminates context window limits altogether. It can manage entire software projects over millions of tokens by intelligently pruning its history while preserving critical context.
To put this in practical terms: a million tokens translates to roughly 750,000 words, or about 1,500 pages of text. You can now feed an AI system an entire regulatory framework, a complete codebase with documentation, or years of customer correspondence in a single request.
What This Actually Enables
Legal and Compliance Work
Law firms and compliance teams can now analyse entire contracts without breaking them into fragments. A 500-page merger agreement, roughly 375,000 tokens, can be processed in a single pass. The model identifies key clauses, flags potential conflicts, and maintains awareness of how provisions in section 3 relate to definitions in section 47. This wasn't reliably possible when documents had to be chunked into smaller pieces.
Research on automated building code interpretation shows that long context models can handle entire legal document corpora without requiring retrieval systems or fine-tuning. Domain-specific models processing regulatory and financial texts achieve over 81% accuracy on complex question-answering tasks when given full document context.
Financial Analysis
Financial analysts no longer need to extract isolated metrics from annual reports. They can process entire filings, earnings transcripts, and regulatory submissions together, understanding nuanced relationships between operational metrics and strategic initiatives. Studies using extended financial datasets demonstrate that long context processing enables more sophisticated reasoning than extraction-based approaches.
Market research firms can analyse thousands of customer feedback entries simultaneously, identifying patterns that would be invisible when reviewing individual comments in isolation.
Software Development
This is where the transformation has been most dramatic. Developers can now load entire codebases, including source files, tests, and documentation, into context. The model understands project architecture, identifies cross-file dependencies, and suggests improvements that account for the complete system design.
Multi-agent systems using long context for fault localisation have successfully identified 157 out of 395 bugs with top-1 accuracy on standard benchmarks, outperforming approaches that only see isolated code fragments. The shift from file-level to project-level understanding changes what's possible in automated code review and refactoring.
Enterprise Knowledge Management
Organisations can create knowledge assistants that genuinely understand relationships across their document collections. Rather than returning keyword-matched excerpts, these systems provide coherent answers that synthesise information from technical manuals, compliance documents, and operational guides. A manufacturing company can build a support system that references multiple sources while maintaining awareness of product-specific constraints.
The Limitations You Need to Know
Before restructuring your entire AI strategy around long context, it's worth understanding the current limitations. The technology is powerful, but comes with constraints.
The "Lost in the Middle" Problem
Research consistently shows that models perform best when critical information appears at the beginning or end of the context window. Information buried in the middle often gets overlooked, even in models specifically designed for long contexts. This creates a characteristic U-shaped accuracy curve across positions.
The mechanism behind this is architectural: attention layers in transformer models cause earlier parts of input sequences to be used more frequently during reasoning. As models add more layers, this positional bias amplifies. While newer models have improved, the effect persists. Gemini 3 Pro's benchmark results on 1 million token retrieval tasks show meaningful improvement over previous generations, but performance still varies significantly based on where relevant information appears.
For practical applications, this means you shouldn't simply feed a large document into a model and expect consistent accuracy across all sections. Strategic prompt construction, placing critical information at the beginning when possible, improves results.
Context Length Itself Hurts Performance
Research from 2025 reveals something more troubling: longer contexts degrade performance even when retrieval isn't an issue. Systematic experiments across major models on maths, question answering, and coding tasks showed that even with all relevant information placed at the optimal beginning position, performance still dropped 14% to 85% as input length increased.
This suggests limitations in how transformers process extensive context during reasoning, beyond simple attention mechanism issues. The practical implication: more context isn't always better. Sometimes a well-curated subset of information produces superior results to dumping everything into the prompt.
Reliability Variations
Stress testing reveals significant reliability differences between models. Some achieve over 96% accuracy with graceful degradation across 100,000+ tokens. Others, despite strong standard benchmark scores, collapse to near-zero accuracy under context stress, exhibiting confident hallucination from early checkpoints.
Model size alone doesn't predict reliability. Testing and evaluation matter enormously when selecting models for production applications that depend on long context accuracy.
Long Context vs RAG: A Practical Framework
One of the most common questions we encounter at StableWorks is whether organisations should use long context models directly or implement Retrieval-Augmented Generation (RAG) architectures. The answer depends on your specific situation.
When Long Context Works Best
Long context approaches excel when your data is relatively self-contained and under 1 million tokens. If you're analysing a single book, a complete codebase, or a lengthy contract, direct processing often produces better results. Tasks requiring understanding of relationships between widely separated sections benefit from having everything in context. Literary analysis, architectural design review, and legal document interpretation often fall into this category.
Long context also makes sense when query volume is low enough that higher per-query costs are acceptable, when documents have complex internal cross-references that chunking would break, or when privacy regulations mandate keeping everything on-premise without external vector databases.
When RAG Makes More Sense
RAG architectures shine when your knowledge base exceeds available context windows, which remains common despite expanded limits. If you're searching across terabytes of documents, RAG's pre-filtering becomes essential. Cost and latency constraints also favour RAG: real-world testing shows RAG queries can cost 1,250 times less than full long context processing, with response times of 1 second versus 45 seconds for million-token contexts.
RAG also provides better explainability and citation capabilities. When you need to trace exactly which source documents informed an answer, retrieval systems make this straightforward. For customer support applications requiring real-time response, RAG's speed advantage is often decisive.
The Hybrid Approach
Increasingly, sophisticated deployments combine both approaches. Use RAG to identify relevant documents from a massive corpus, then apply long context processing for deep analysis of the filtered set. This achieves 3-5x cost reductions versus pure long context while maintaining 95%+ accuracy.
Emerging architectures like "Order-Preserving RAG" find optimal chunk counts, typically 20-30% of full context, achieving higher quality with fewer tokens than either pure approach. These hybrid systems represent where enterprise AI is heading: intelligent routing that selects the right approach for each query automatically.
Cost Realities
Understanding pricing is essential for budgeting and architecture decisions. Current rates vary significantly across providers.
Gemini 3 Pro costs $2 per million input tokens and $12 per million output tokens for prompts under 200,000 tokens, doubling beyond that threshold. Claude Sonnet 4 charges $3/$15 per million tokens for standard contexts, increasing to $6/$22.50 for contexts exceeding 200,000 tokens. GPT-5 prices at $1.25/$10 per million tokens for the standard model, with nano variants available at $0.05/$0.40.
Context caching transforms economics for applications with repeated queries against similar documents. Cached tokens typically cost 90% less than fresh tokens. For a document Q&A system processing 1,000 queries against the same 100,000 token knowledge base, caching reduces costs from roughly $100-125 to $10-15 after initial cache population.
Model cascading offers another optimisation path: route simple queries to inexpensive models while reserving premium models for complex reasoning. Well-implemented cascading systems achieve 87% cost reduction by ensuring expensive models handle only the 10% of queries requiring their capabilities.
Security and Privacy Considerations
Long context processing introduces distinct data privacy challenges. When you upload entire document repositories to cloud-based APIs, you're potentially exposing sensitive business information, customer data, and intellectual property. While enterprise providers offer privacy assurances, including commitments not to train on customer data, regulatory frameworks like GDPR and HIPAA often mandate stricter controls.
The unintentional exposure risk increases with context window size. Employees may inadvertently include confidential information when uploading large documents. Robust data protection requires employee training, automated scanning for sensitive content, and strict access controls.
For highly regulated industries, on-premise deployment of open-source long context models often becomes necessary despite their operational costs and typically shorter context windows. This allows organisations to maintain complete data control while meeting compliance requirements.
What's Coming Next
The trajectory suggests continued expansion, with 5-10 million token windows expected to become standard in flagship models by 2026. However, the emphasis is shifting from raw capacity to effective utilisation. Advertising a 10 million token window means little if models can't reliably use information throughout that range.
Infinite context approaches, like Google's Infini-attention, maintain compressed memory of previously processed content while handling new information. These systems could theoretically process unlimited context with bounded computational resources. Early demonstrations show 114x memory compression while maintaining over 99% retrieval accuracy.
The emergence of "compaction" techniques in models like GPT-5.1-Codex-Max hints at a future where context window limits become less relevant. Instead of hard capacity constraints, models will intelligently manage what they remember based on relevance and task requirements.
Multimodal integration will mature substantially. Current models handle text, images, and code, but future systems will seamlessly process video, audio, and interactive elements within unified long context frameworks. This enables applications like analysing hours of video meetings alongside associated documents and communications in a single context.
Practical Recommendations for Traditional Businesses
For organisations beginning to explore these capabilities, a few principles apply.
Start with constrained pilots. Choose a specific use case, perhaps contract analysis for your legal team or codebase documentation, and test thoroughly before expanding. Long context processing isn't uniformly superior; discover where it genuinely outperforms alternatives in your context.
Test positioning sensitivity. Before deploying, experiment with placing critical information at different positions within your prompts. If results vary dramatically based on where key details appear, your use case may require additional engineering to work reliably.
Consider hybrid architectures from the start. Pure long context approaches rarely offer optimal cost-performance trade-offs. Design systems that can intelligently route between RAG and long context processing based on query characteristics.
Budget for caching infrastructure. If you're processing repeated queries against similar documents, context caching transforms economics. Build this into your architecture rather than treating it as an optimisation for later.
Evaluate models under stress. Standard benchmarks don't reveal how models behave at the edge of their capabilities. Test with your actual document sizes and complexity levels before committing to a specific provider.
The Bottom Line
The expansion of context windows from thousands to millions of tokens represents a genuine capability shift. Tasks that were previously impossible, impractical, or required significant engineering workarounds are now accessible through straightforward API calls.
That said, long context isn't a universal solution. Understanding where it excels, where it struggles, and how to optimise costs matters as much as understanding that the capability exists. The organisations that benefit most will be those that approach these tools thoughtfully: identifying specific use cases where extended context genuinely helps, testing rigorously before deployment, and building hybrid systems that use the right approach for each task.
The context window revolution is real. Making it work for your business requires treating it as a powerful tool with specific strengths and limitations, rather than a magic solution to all document processing challenges.
More Articles
Written by
Aaron W.
Nov 24, 2025
The Context Window Expansion and What It Means for Your Business
Context windows expanded 1,000x in five years, enabling AI to process entire contracts, codebases, and document libraries in one pass. Practical guide to capabilities, limitations, costs, and when to use long context versus RAG.
Written by
Aaron W.
Nov 24, 2025
The Context Window Expansion and What It Means for Your Business
Context windows expanded 1,000x in five years, enabling AI to process entire contracts, codebases, and document libraries in one pass. Practical guide to capabilities, limitations, costs, and when to use long context versus RAG.
Written by
Aaron W.
Nov 24, 2025
The Context Window Expansion and What It Means for Your Business
Context windows expanded 1,000x in five years, enabling AI to process entire contracts, codebases, and document libraries in one pass. Practical guide to capabilities, limitations, costs, and when to use long context versus RAG.
Written by
Aaron W.
Oct 24, 2025
The Real Business Impact of AI According to 2024-2025 Data
Research from 2024-2025 reveals that strategic AI implementation delivers 3-10x ROI while 95% of companies see zero returns, with success determined by investment levels, data infrastructure maturity, and treating AI as business transformation rather than technology adoption.

Written by
Aaron W.
Oct 24, 2025
The Real Business Impact of AI According to 2024-2025 Data
Research from 2024-2025 reveals that strategic AI implementation delivers 3-10x ROI while 95% of companies see zero returns, with success determined by investment levels, data infrastructure maturity, and treating AI as business transformation rather than technology adoption.
Written by
Aaron W.
Oct 24, 2025
The Real Business Impact of AI According to 2024-2025 Data
Research from 2024-2025 reveals that strategic AI implementation delivers 3-10x ROI while 95% of companies see zero returns, with success determined by investment levels, data infrastructure maturity, and treating AI as business transformation rather than technology adoption.
Written by
Aaron W
Oct 17, 2025
When Uncertainty Becomes the Safety Signal: How AI Companies Are Deploying Precautionary Safeguards
Anthropic, OpenAI, and Google deployed their newest models with enhanced safety protections before proving they were necessary, implementing precautionary safeguards when evaluation uncertainty itself became the risk signal.

Written by
Aaron W
Oct 17, 2025
When Uncertainty Becomes the Safety Signal: How AI Companies Are Deploying Precautionary Safeguards
Anthropic, OpenAI, and Google deployed their newest models with enhanced safety protections before proving they were necessary, implementing precautionary safeguards when evaluation uncertainty itself became the risk signal.
Written by
Aaron W
Oct 17, 2025
When Uncertainty Becomes the Safety Signal: How AI Companies Are Deploying Precautionary Safeguards
Anthropic, OpenAI, and Google deployed their newest models with enhanced safety protections before proving they were necessary, implementing precautionary safeguards when evaluation uncertainty itself became the risk signal.
